
Na última Black Friday, um grande e-commerce enfrentou um problema clássico: a equipe de marketing queria reagir em tempo real ao comportamento dos usuários — cada clique, cada carrinho abandonado, cada nova compra. Só que o sistema era todo baseado em chamadas síncronas entre APIs.
Resultado? Lentidão, falhas intermitentes e uma sobrecarga que quase derrubou a plataforma.
Foi então que entraram com Apache Kafka: os eventos passaram a ser enviados para um tópico, desacoplando os produtores dos consumidores. A plataforma de vendas seguiu leve, enquanto os times de marketing, recomendação e analytics podiam processar os dados em tempo real, cada um no seu ritmo.
Esse tipo de mudança só é possível quando você conhece os padrões certos e os trade-offs que vêm com eles. É exatamente isso que a gente ensina na Comunidade de Arquitetura Descomplicada (CaD) — construir ambientes resilientes, modernos e que escalam de verdade.
Por que usar o Apache Kafka?
O Kafka vai muito além de uma simples fila de mensagens. Ele é uma plataforma de event streaming — ideal para capturar, processar, armazenar e distribuir eventos em larga escala, em tempo real.
Você deve considerar o Kafka quando precisa de:
- Desacoplamento entre sistemas produtores e consumidores;
- Escalabilidade horizontal de leitura e escrita;
- Persistência dos eventos por horas, dias ou até indefinidamente;
- Alta performance e resiliência em ambientes distribuídos.
Kafka não é só uma fila
Embora dê para usar o Kafka como fila, a comparação é injusta. Ao contrário de filas tradicionais (como SQS, RabbitMQ ou MSMQ), o Kafka tem características únicas:
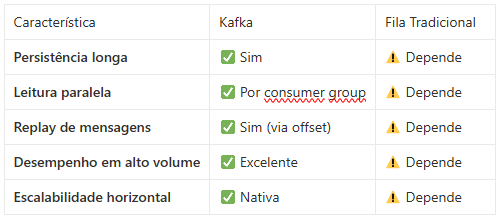
Conceitos-chave do Kafka
> Streaming
Kafka é ideal para processar eventos em tempo real: cliques, sensores, logs, compras, etc. Cada mensagem é um record, que trafega em um tópico. Porém ele não é só usado para isso. Ele também é muito utilizado no lugar de filas para troca de mensagens entre dois microsserviços.
> Distribuído por natureza
Kafka é distribuído: você configura múltiplos brokers (servidores) formando um cluster. Assim, ganha resiliência, performance e escala. A instalação é fácil e a criação de tópicos também!
> Escalabilidade horizontal
Você pode adicionar mais brokers, partições e consumidores conforme o volume aumenta — sem refatorar tudo. Isso é um grande diferencial… Existe também solucões como o AWS Apache Kafka que entrega um kafka já gerenciado.
> Persistência e Durabilidade
As mensagens (records) são armazenadas em disco por um período definido — desde minutos até dias. Isso permite o reprocessamento posterior via offset.
> Desacoplamento entre aplicações
Produtores só se preocupam em enviar eventos. Consumidores se inscrevem nos tópicos que desejam — e o sistema roda mesmo que eles estejam offline.
Estrutura do Kafka
> Brokers
São os servidores onde o Kafka roda. Normalmente você tem um cluster com 3 ou mais brokers.
> Tópico e Partições
Cada tópico pode ter múltiplas partições — que permitem paralelismo no processamento. A escrita é distribuída entre partições com base em round-robin ou chave definida.
> Records
São as mensagens — os dados em si. Ficam armazenados nas partições.
> Replication Factor
Cada partição pode ser replicada em vários brokers, garantindo alta disponibilidade. Ex: replication factor 3 = cada dado existe em 3 nós diferentes.
> Leitura inteligente com offsets
Kafka não apaga a mensagem após consumo. O que muda é o offset — o ponteiro que diz até onde o consumidor já leu. Ou sejá, é um index dizendo onde parou.. você pode facilmente muda-lo. Se um consumidor falhar, basta mover o offset para reler as mensagens.
> Consumer Groups
Vários consumidores podem processar o mesmo tópico em paralelo, desde que pertençam ao mesmo consumer group. Isso evita leitura duplicada e garante balanceamento automático.
Exemplo:
- Consumer A1, A2, A3 — todos no grupo “pagamentos”
- Cada um recebe partições diferentes do tópico “vendas”
- Nada se repete, tudo paralelizado!
E se um novo grupo entrar (ex: “relatórios”), ele consome todas as mensagens desde o início — com seu próprio offset.
> Estratégia de distribuição
Você pode configurar partições para refletir o negócio:
- Clientes premium vão pra partições exclusivas
- Serviços sensíveis recebem mais réplicas
- Pode aplicar sharding por região, plano, etc.
🚀 Conclusão
O Apache Kafka é muito mais do que uma fila de mensagens. É um pilar para arquiteturas modernas, desacopladas, escaláveis e resilientes.
Mas lembre-se: com grande poder vem grande responsabilidade. Kafka traz complexidade — e não é a melhor escolha para todos os cenários. as vezes um simples servico de mensageria é o suficiente.
Saber quando usar (e quando não usar) é o que separa arquiteturas sustentáveis de soluções improvisadas.
E é esse tipo de decisão, com base técnica e visão de longo prazo, que a gente ensina e discute o tempo todo na Comunidade de Arquitetura Descomplicada (CaD).





