
“Dá uma checada no serviço aí pra mim?”
Se você já ouviu isso no meio de uma sprint, incidente ou code review… sabe o quanto essa frase pode ser frustrante.
Checar o quê? Baseado em quê? Só porque a API respondeu com 200 e os botões do front renderizaram, quer dizer que está tudo saudável?
A gente precisa parar com o achismo. E começar a definir o que realmente significa um sistema saudável.
É aí que entram os famosos (e muitas vezes ignorados):
SLI, SLO e SLA
O que são SLI, SLO e SLA? (Com exemplos reais)
SLI – Service Level Indicator
É a métrica crua que você está observando. Exemplo:

SLO – Service Level Objective
É o acordo técnico (interno) sobre qual é o valor mínimo aceitável para aquele SLI. Exemplo:
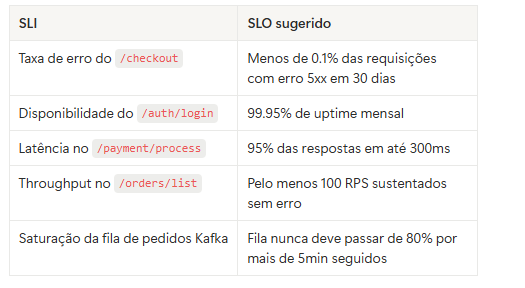
SLA – Service Level Agreement
É o acordo formal com cliente ou time de negócios. Exemplo:
“Se a disponibilidade mensal do /auth/login ficar abaixo de 99.5%, há penalidade contratual de X reais.”
A gente não vai se aprofundar em SLA aqui, porque o foco é você construir visibilidade real e acordos técnicos confiáveis no seu time com SLI + SLO.
Um exemplo prático (com template)
Imagine que você tem uma API de pagamento rodando em container no Kubernetes. Aqui vai uma tabela com exemplos reais de SLIs/SLOs que você pode usar como base para implementar observabilidade + alarmes.
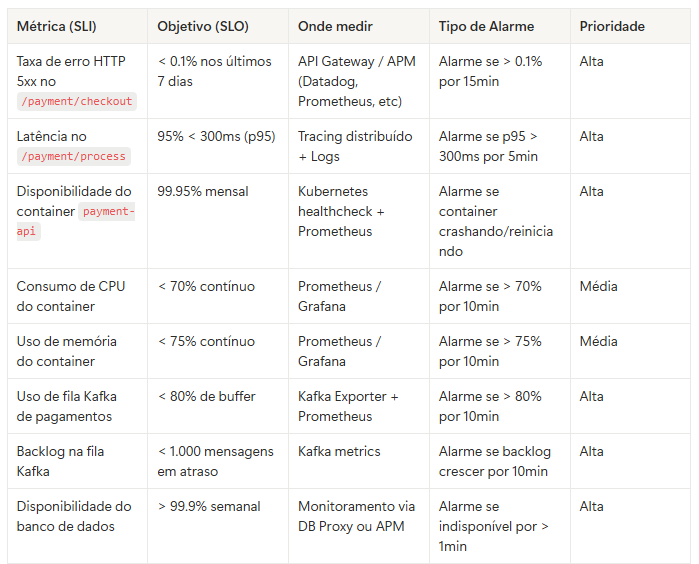
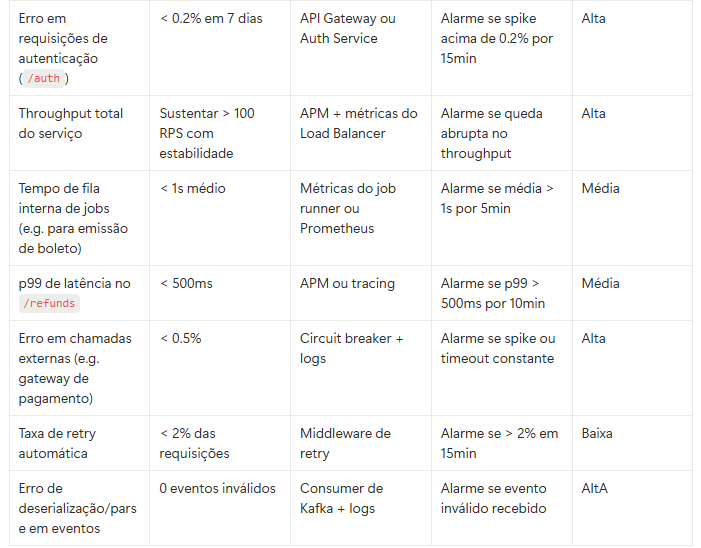
Agora é com você:
Essa tabela acima é só um exemplo. Cada sistema tem suas características, pontos críticos e necessidades específicas.
O que você pode (e deve) fazer agora:
- Escolha um microserviço do seu sistema
- Liste os endpoints e responsabilidades principais
- Defina 5 a 10 SLIs reais que representam o que “saúde” significa ali
- Para cada SLI, defina um SLO
- Configure monitoramento e alarmes baseados nesses SLOs
- Compartilhe com o time (não adianta nada se só você souber)
Pra fechar: e se tudo isso virasse cultura?
Agora imagina só…
Você com todos esses SLIs bem definidos, seus SLOs visíveis num dashboard, alarmes configurados com critérios claros — e o time inteiro sabendo exatamente o que é um sistema saudável.
Ficaria bem mais fácil tomar decisões, certo?
- Saber quando é hora de agir (e quando não é)
- Ter clareza sobre saúde do sistema, sem depender de achismos
- Evitar trabalho repetitivo e sem propósito (o famoso Toil Work, lá nos princípios de SRE)
- Focar no que realmente importa: entregar valor com estabilidade
SLO não é pra virar planilha de gaveta.
É pra ser usado todos os dias como bússola da confiabilidade.
Quer aprender MAIS ?
Se você curte essa pegada — visibilidade, métricas que importam, decisões técnicas mais maduras — então vem com a gente.
Na Comunidade de Arquitetura Descomplicada (CaD) a gente compartilha conteúdo que de fato vão agregar para sua carreira e aumentar a resiliência dos seus produtos.
Tudo sobre como construir sistemas resilientes, modernos e que não explodem em produção.
Te espero lá. Abraços e até a próxima! 👋





