
Sabe quando você sente que a sua aplicação tá “pesada”, travando ou demorando pra responder — e fica aquela dúvida se o problema tá no tempo de resposta ou na quantidade de requisições simultâneas?
Pois é… você não tá sozinho. Essa dúvida entre latência e throughput é mais comum do que parece — e entender a diferença entre os dois é fundamental pra conseguir otimizar sua arquitetura de forma estratégica.
Não entender essas duas métricas — isoladamente e em conjunto — faz com que muitas decisões arquiteturais críticas sejam negligenciadas. E o pior: você até escala, mas carrega os problemas junto e a vezes o custo fica super alto. Em sistemas modernos, não dá pra crescer sem dominar o comportamento de latência e throughput.
Mas afinal, o que é Latência?
Latência é o tempo que uma única chamada leva pra ser processada — do momento em que o cliente faz uma requisição até a resposta final. Medimos isso em milissegundos, segundos (em casos extremos), e usamos percentis como p95, p99 pra entender o comportamento nos piores cenários.

E o que é Throughput?
Já throughput é a quantidade de transações que o sistema consegue processar por segundo (ou por minuto, hora, etc). A famosa métrica TPS — transactions per second.
É importante entender que throughput e latência não competem entre si, mas se influenciam. Quanto maior o throughput, maior a chance da latência subir — e é aí que mora o caos quando não se tem controle e visibilidade sobre isso.

Reforçando…
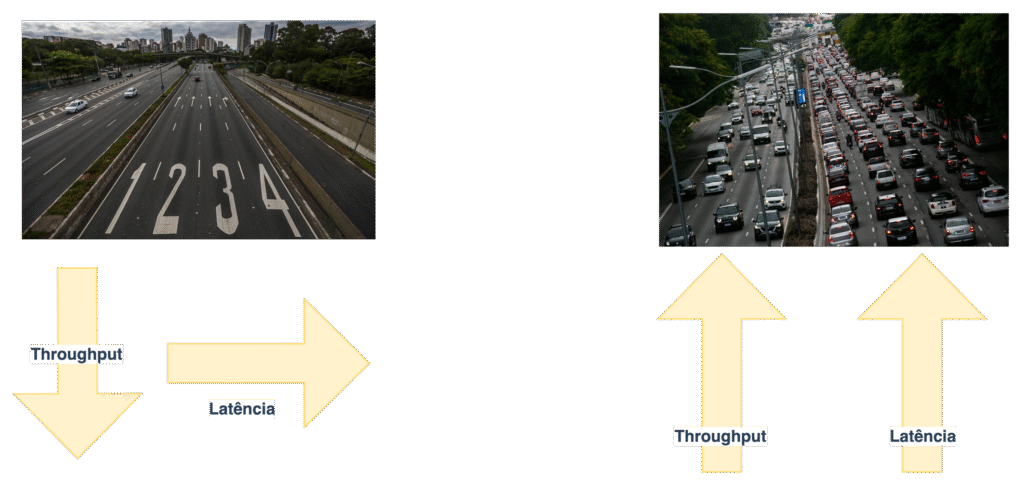
Imagina uma rodovia:
- Latência é o tempo que um carro leva pra atravessar o trajeto.
- Throughput é quantos carros passam por minuto na pista.
Se a via estiver vazia, cada carro (requisição) passa pela via sem concorrência. Mas se estiver congestionada, o carro aguarda a liberação da via e a latência aumenta.
Se seu sistema tá lento, a pergunta real não é “o que tá travando”, mas sim:
“É uma única transação que está lenta ou são muitas chegando ao mesmo tempo?”
E a resposta disso vai definir como você vai atacar o problema.
Como Melhorar a Latência?
- Cache e CDN: Deixar os dados mais próximos do usuário. Em vez de buscar dados em servidores distantes, use cache local, Redis, Memcached, ou CDN para conteúdo estático.
- Evitar chamadas síncronas desnecessárias: Se o usuário não precisa esperar o processamento, envie a mensagem para uma fila e retorne uma resposta imediata. Isso alivia a pressão da latência.
- Banco de dados eficiente: Otimize queries, crie views materializadas e avalie cardinalidade. Pode ser que a lentidão esteja no banco.
- Eficiência de código (Big O): Analise a performance do seu algoritmo. Pequenas melhorias podem gerar grandes ganhos em tempo de execução.
- Reduzir hops de rede: Evite arquiteturas com muitos microsserviços em cascata ou que dependam de vários componentes em sequência. Cada “hop” adiciona tempo.
Como Melhorar o Throughput?
- Escalabilidade horizontal: Separe leitura de escrita, distribua carga entre instâncias. Adicionar mais nós geralmente ajuda no throughput.
- Processos assíncronos e paralelismo: Use filas e workers. Em vez de bloquear um endpoint esperando processamento, use workers em background para processar.
- Sharding e réplicas: Quando a carga está muito alta, divida os dados por conjunto de usuários ou crie réplicas para leitura.
- Batching: Ao invés de processar item por item (como em requisições REST repetidas), envie um lote de dados para processamento. Isso reduz o número de chamadas e melhora a eficiência.
- Balanceamento de carga inteligente: Não dependa apenas do round-robin padrão. Avalie algoritmos como least connections ou hash-based para distribuir melhor a carga.
Conclusão
Latência e throughput são conceitos diferentes, mas diretamente relacionados. Melhorar um sem comprometer o outro é uma arte na arquitetura.
Muitas vezes, ao analisar a arquitetura de uma aplicação ou as decisões documentadas em um ADR (Architecture Decision Record), fica claro como a confusão entre esses dois conceitos levou a soluções questionáveis. Já vi muitos casos onde a escolha foi aumentar o throughput achando que isso resolveria problemas de latência — o que raramente é verdade.
Exemplo: Em um projeto de e-commerce que acompanhei, a equipe decidiu aumentar a quantidade de instâncias do serviço de checkout, acreditando que isso reduziria o tempo de resposta. Resultado? A origem da lentidão estava em uma query não indexada no banco de dados, a latência continuou alta — e o custo da infraestrutura aumentou sem resolver o problema real.
Aguentar mais throughput não significa melhorar a latência. Cada métrica tem seu papel e precisa ser tratada com estratégias específicas.
E você, já teve algum caso que gostaria de compartilhar ? não deixe de mandar pra mim, quem sabe seu case não seja assunto para um próximo newsletter !!
🚨Se curtiu esse conteúdo e quer aprender mais sobre arquitetura de software em um nível bem mais aprofundado, venha fazer parte da Comunidade de Arquitetura Descomplicada (CaD)! Saiba mais em https://mugnos-it.com/cad/ 🚀🚨
<< SAIBA MAIS NA VERSAO DO VÍDEO >> : https://www.youtube.com/watch?v=dZRThlz20NU&t
Até a próxima!





