
O Inimigo Oculto da Concorrência!
👋 Fala, galera!
Imagine que você implementou um sistema bonitinho, testado, com métricas no ar, deploy redondo… tudo certo. Até que, do nada, começa a aparecer um bug esquisito. Inconsistências de dados, valores errados, comportamentos aleatórios. E, no meio da investigação, alguém solta aquele diagnóstico misterioso:
“Ah… isso aí deve ser Race Condition.”
Parece nome de vilão da Marvel, né? Mas na real, Race Condition é um dos erros mais traiçoeiros em sistemas concorrentes — justamente por ser difícil de reproduzir, difícil de explicar e, muitas vezes, ignorado até estourar de vez.
Já passei pro isso algumas vezes, algumas vezes eu não tinha detalhes suficientes para entender se realmente era um caso de “race condition” mesmo, teve casos que eu realmente presenciei ele acontecendo com meu código e outras vezes que na verdade o termo foi usado para justificar algo que não tinha relação nenhuma com race condition…
Então bora entender o que realmente está por trás desse problema, por que ele acontece e o mais importante: como evitar esse caos silencioso e não passar vergonha falando coisa errada .
→ O Que É Race Condition?
Em termos simples, Race Condition é o que acontece quando dois ou mais processos tentam acessar ou modificar o mesmo recurso ao mesmo tempo, e a ordem de execução impacta diretamente no resultado final.
É uma corrida. Só que, diferente da Fórmula 1, aqui ninguém avisa quem vai largar primeiro — e quem perde é o seu sistema.
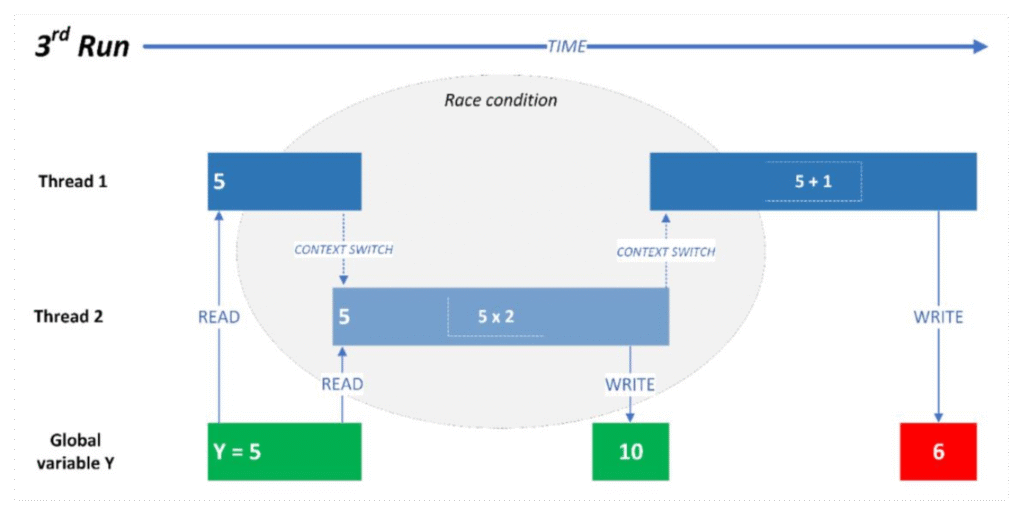
Um exemplo real e comum:
- Duas threads leem o valor de uma variável global
y = 5; - A primeira quer somar
1, a segunda quer multiplicar por2; - A segunda escreve
10antes; - A primeira, achando que ainda era
5, soma1e sobrescreve6no final.
Resultado esperado: 11. Resultado real: 6. Clássico Race Condition.
→ Quando Pode Acontecer?
Muita gente acha que Race Condition é um “problema de thread”. Mas não é só isso.
Ele pode acontecer em qualquer situação com concorrência e estado compartilhado, por exemplo:
- Threads paralelas acessando a mesma variável ao mesmo tempo. Clássico.
- Vários pods atualizando um valor em cache (tipo Redis) sem atomicidade.
- Microsserviços diferentes escrevendo na mesma base de dados simultaneamente.
- Bancos sem isolamento transacional permitindo sobrescritas silenciosas.
- Escritas concorrentes em arquivos, contadores globais ou estados compartilhados.
E o mais traiçoeiro: ele não dá erro.
Ele só… dá errado.
E quando você percebe, o estrago já foi. 😬
→ Como Evitar esse Caos?
Ok, ok, não vou falar só do problema.. Segue aqui algumas formas de você evitar que o race condition aconteca de forma eficaz.
- Mutex / Lock Impeça o acesso simultâneo a recursos com locks. Exemplo: ao invés de deixar duas threads editarem a variável, use um
mutexpara garantir que apenas uma por vez consiga acessar. 💡 Ideal pra quando você realmente precisa editar um valor compartilhado. - Fila + Worker
Ao invés de editar diretamente, jogue todas as requisições para uma fila interna, e um único processo (ou thread) processa as mensagens uma a uma.
💡 Estratégia ótima para incrementos, contadores ou qualquer operação repetida.
- Atomicidade Aqui a ideia é simples: ou tudo acontece, ou nada acontece. Seja via transação no banco, comandos atômicos em cache (
INCR,SETNX), ou lógica na aplicação com controle de estado. 💡 Útil quando várias operações dependem de consistência total em um único recurso. - Leader Election / Flags de execução Antes de atualizar algo, a aplicação verifica se “tem permissão” para isso. Pode ser uma flag na memória, uma verificação de estado ou até um algoritmo de eleição de líder. 💡 Útil quando múltiplos processos querem disputar um mesmo recurso. Ex Maquina de estado.
IMPORTANTE: Cada cenário pode exigir uma ou mais dessas estratégias. O importante é sempre se perguntar:“Esse recurso pode ser acessado ao mesmo tempo por mais de um processo?” Se sim, previna antes de escalar.
Conclusão:
Race Condition nem sempre é um bug.Na maioria das vezes, é um débito técnico que a gente deixa escapar na hora de implementar — por falta de atenção ao fluxo real da concorrência.
Por isso, mais do que aplicar mutex, filas ou atomicidade, é essencial entender de verdade o que o código está fazendo e quais caminhos de execução podem ocorrer em paralelo. Sem esse entendimento, a gente só empurra o problema pra frente.
E o cenário hoje não ajuda: ambientes distribuídos estão cada vez mais presentes. A gente sabe que precisa “dividir para conquistar”, mas, quanto mais divide, maior o risco de concorrência mal resolvida.
O que era raro num sistema monolítico centralizado, agora pode acontecer em qualquer serviço, pod, thread ou evento assíncrono.
Enfim… Se quiser aprofundar ainda mais esse tipo de conhecimento e se tornar uma referência em arquitetura de sistemas, vem com a gente na Comunidade de Arquitetura Descomplicada (CaD).
Por aqui a gente estuda, discute e aplica os padrões que fazem diferença de verdade na prática — seja você dev, tech lead ou arquiteto.
👉 Saiba mais em: https://mugnos-it.com/cad
Abraços.
Douglas Mugnos





