Feature Flags: Full Control Without Redeploys

It was supposed to be just another simple release. The team had rewritten a critical feature — everything tested, validated, looking clean. Deployment done, everything live. But all it took was an unexpected behavior with a specific group of users… and that was it: operations stalled, incidents started popping up everywhere, and the rollback turned […]
DevOps vs SRE vs Platform Engineering
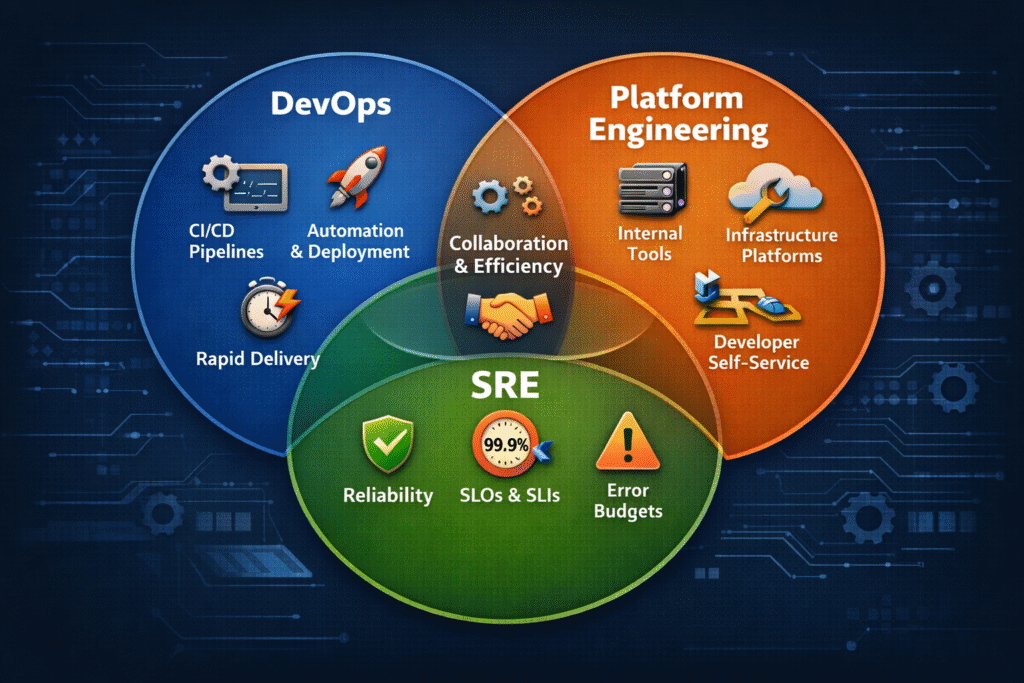
👋 Hey, Here we are again… talking about roles and responsibilities in modern engineering teams. And let’s be honest: this topic almost always generates confusion. Ask five companies what DevOps, SRE, or Platform Engineering means and you’ll probably get five slightly different answers. Titles vary, responsibilities shift, and the boundaries are not always clear. But […]
Leveraging AI to define SLIs and SLOs

Following up on last week’s analysis of Evernote’s transition to a Site Reliability Engineering (SRE) model, today we address the most common bottleneck teams face when adopting these practices: the “blank page syndrome.” It is easy to understand the theory behind Error Budgets, but translating a complex system architecture into precise, mathematically sound Service Level […]
5 Tips to Stand Out as a Tech Lead, Staff or Staff +

Have you ever stopped to think that a Tech Lead might be the “platypus” of technology? Calm down, I’ll explain. The platypus swims, but it’s not the best swimmer. It has a duck’s bill, but it’s not a duck. It lays eggs, but it’s a mammal. At the end of the day, it can do […]
Avoid deployment disasters: Choose the right strategy!

Hey everyone, If there’s one thing nobody wants, it’s a deployment that negatively impacts the business. Choosing the right deployment strategy is not just a technical decision — it’s a necessity to ensure availability, stability, and user experience. Every change in your system carries risk. A deployment mistake can cause downtime, impact users, and worse […]
Static Stability: Is Your Infrastructure Truly Resilient?

Today I want to bring you a reflection that, if you haven’t had it yet, you probably will soon — especially if you work (or want to work) with distributed systems, high availability, or cloud environments. After all… does using one, two, or even three data centers really make your application more resilient and therefore […]
What is the importance of defining good SLIs, SLOs, and SLAs?

“Can you take a look at the service for me?” If you’ve ever heard that in the middle of a sprint, incident, or code review… you know how frustrating that sentence can be. Check what? Based on what? Just because the API returned 200 and the front-end buttons rendered, does that really mean everything is […]
Why should everyone know the principles of SRE? 🔧📈

Learning SRE principles was an important step in maturing my view of resilient systems — especially when it comes to keeping what we build running well in the day to day and over time. No, I’m not just talking about monitoring, automated deploys, or alerts. I’m talking about the philosophy behind all of it. SRE […]
Como ser um SRE mais produtivo ?

Hoje me perguntaram algo simples — mas que me fez refletir bastante. “Por que você realmente precisa de uma licença de Claude Code para fazer seu trabalho?” Ao invés de responder de forma subjetiva, eu fiz algo bem direto: criei uma pequena tabela comparando tempo tradicional de execução vs tempo usando IA. Nada super científico. […]
IA não resolve incidentes sozinha (e isso é uma boa notícia)!

Há muitos anos, quando eu falava sobre coreografia vs orquestração em arquitetura, uma coisa já era muito clara pra mim: orquestrar sempre foi mais poderoso do que apenas reagir a eventos. E eu acho que essa mesma analogia se aplica perfeitamente a utilização de IA para resolver problemas. Quando falamos de incidentes, não pedir pra […]