👋 Hey,
Here we are again… talking about roles and responsibilities in modern engineering teams.
And let’s be honest: this topic almost always generates confusion.
Ask five companies what DevOps, SRE, or Platform Engineering means and you’ll probably get five slightly different answers. Titles vary, responsibilities shift, and the boundaries are not always clear.
But even though companies interpret these roles differently, each one exists to solve a specific problem in the software lifecycle. Understanding those differences is important—not just for clarity, but also to empower teams to collaborate better and build more resilient systems.
So let’s unpack this a bit.
The Lines Are More Fluid Than We Think
One interesting thing about our industry is that roles often overlap.
An engineer provisioning infrastructure with automation tools like Ansible and running Kubernetes clusters might easily be called a DevOps engineer.
A systems engineer building monitoring systems and reliability tooling might be seen as an SRE.
The truth is: these lines are fluid. And that’s actually what makes the industry exciting.
Good operators and engineers constantly borrow practices from multiple disciplines.
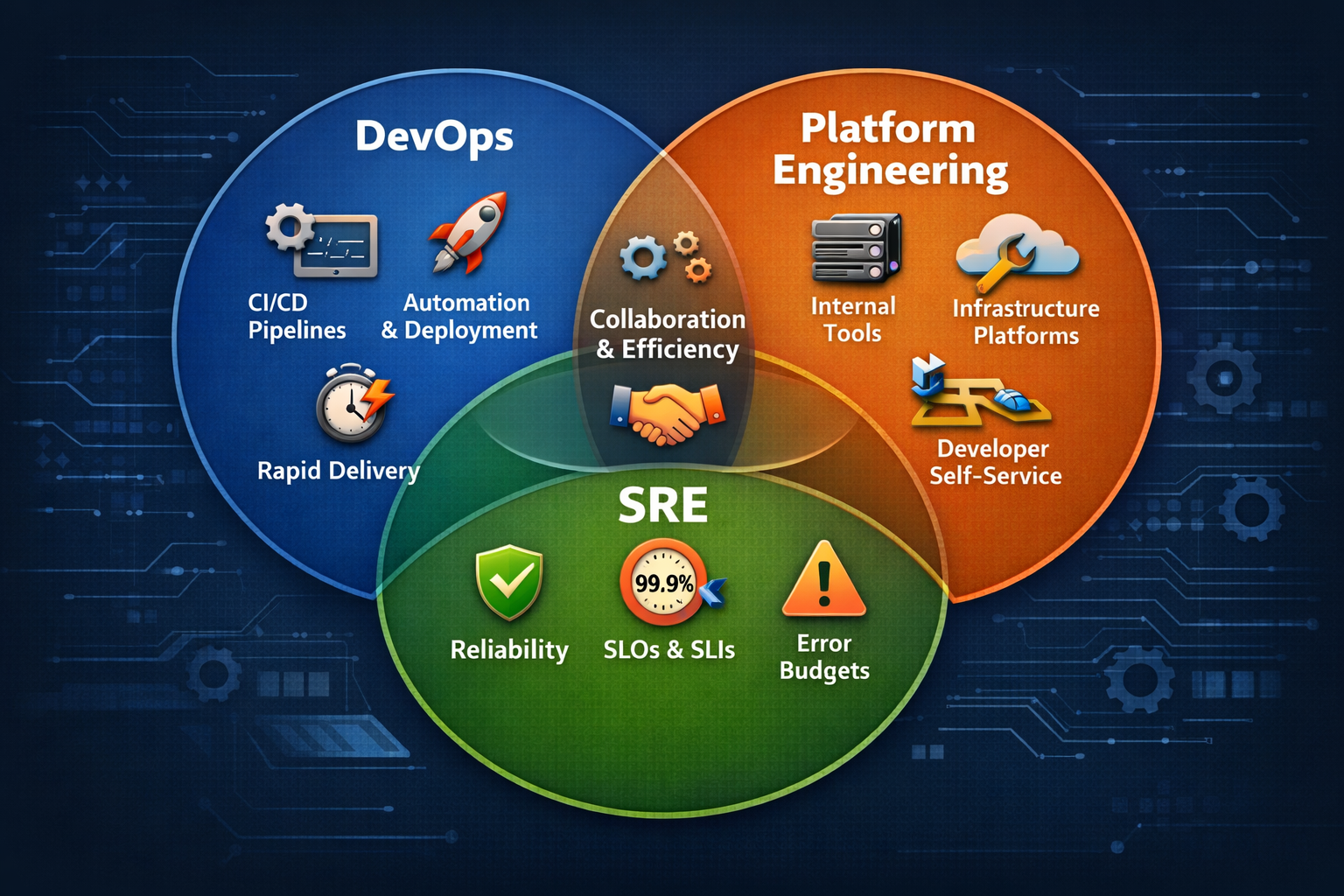
DevOps: Speed and Flow in Software Delivery
Let’s start with DevOps, because historically it came first.
DevOps emerged to solve a very specific problem:
the silos between development and operations teams.
Before DevOps, developers wrote code and threw it over the wall to operations teams. Ops teams then had to deploy, run, and troubleshoot systems they didn’t build.
DevOps introduced a new approach focused on:
- Collaboration between teams
- Automation
- Continuous Integration and Continuous Delivery
- Faster feedback loops
The central DevOps question is simple:
How do we deliver software faster and with less friction?
DevOps focuses heavily on delivery pipelines, automation, and the flow of software through the SDLC.
But there’s an important limitation here.
Speed alone does not guarantee stability.
SRE: Engineering Reliability
This is where Site Reliability Engineering (SRE) enters the picture.
Originally created at Google, SRE introduced a key idea:
Reliability is not just an outcome — it’s an engineering discipline.
SRE teams focus on ensuring that systems can survive the chaos of real-world traffic, failures, and scale.
Instead of treating reliability as an abstract goal, SRE makes it measurable and manageable through concepts like:
- SLIs (Service Level Indicators) – what we measure
- SLOs (Service Level Objectives) – the reliability targets
- Error budgets – how much failure the system can tolerate
This changes how decisions are made.
If the system is within its error budget, teams can move fast and ship new features.
If reliability starts degrading, feature development pauses and stability becomes the priority.
In simple terms:
DevOps accelerates delivery. SRE defines the safe operating speed of the system.
Without DevOps, you struggle to scale delivery.
Without SRE, you scale… until things break.
SREs also tend to stay closer to the business impact of systems. They participate in defining reliability targets and ensure that systems actually deliver the level of service expected by the business.
Platform Engineering: Building the Internal Platform
Now let’s talk about Platform Engineering.
Platform teams focus on building internal platforms that simplify software development and operations for the rest of the organization.
Instead of every team reinventing infrastructure and operational practices, the platform team provides a self-service environment.
Think about it as an internal product for developers.
Companies like Netflix and Spotify are well-known examples of this model. Their platform teams create infrastructure and tooling that allow developers to focus primarily on building product features.
The platform handles the “nuts and bolts” of running software.
This often includes things like:
- Deployment platforms
- Observability tooling
- CI/CD pipelines
- Infrastructure abstractions
- Golden paths for developers
Platform Engineering acts as the connective tissue between development and operations, enabling teams to move faster without constantly reinventing operational foundations.
Where SRE and Platform Engineering Meet
This is where things get interesting.
An SRE can absolutely be part of a Platform Engineering team, and in many companies that’s exactly what happens.
But the two roles are not identical.
Platform Engineers typically focus on building reusable systems and internal platforms that enable developers.
SREs focus on ensuring that real production systems behave reliably under real conditions.
Another way to look at it:
- Platform Engineering builds the road.
- SRE ensures the cars can safely drive at scale without crashing.
Both roles care deeply about reliability, but their perspectives are different.
Platform teams deliver capabilities.
SRE teams validate real-world reliability outcomes.
And sometimes SREs are the ones knocking on the door saying:
“This system is not meeting the reliability targets.”
The Reality: These Roles Should Coexist
Despite all the debates online, the reality is much simpler.
DevOps, SRE, and Platform Engineering are not competing ideas.
They solve different problems:
- DevOps improves delivery flow
- SRE ensures measurable reliability and resilience
- Platform Engineering builds internal platforms that scale development
When combined correctly, they create an ecosystem where teams can deliver software quickly without sacrificing stability.
So… Which One Should You Be?
Here’s the interesting part.
If you’re an SRE or a Platform Engineer, moving between these roles is often quite natural. Both require deep understanding of systems, automation, observability, and distributed architectures.
DevOps, on the other hand, tends to stay closer to development workflows and delivery pipelines, though strong DevOps engineers also develop strong operational knowledge over time.
But the truth is: a strong engineer in any of these pillars usually has the skills to transition between them.
Because at the end of the day, all three roles share a common goal:
building modern, resilient, high-quality systems.
And that’s what really matters.
That’s what I had for today.
See you next time 👋





